エッジは、領域境界の表現にリンクされている必要がある。この表現は輪郭と呼ばれる。輪郭は開いている場合もあるし閉じている場合もある。閉じた輪郭は領域境界に対応し、領域内のピクセルは塗りつぶしアルゴリズムによって検出される。開いた輪郭は、領域境界の一部である場合がある。領域間のコントラストが十分でないため、エッジ検出器が境界に沿ったエッジを検出できないことがあるため、領域境界にギャップが生じることがある。エッジ検出のしきい値が高すぎるか、境界のある部分に沿ったコントラストが画像の他の領域に比べて弱すぎて、画像内のどこでも機能する単一のしきい値がない可能性がある。開いた輪郭は、線分が互いにつながっているいる場合にも発生する。たとえば、描画や手書きのサンプルで、線分がストロークに沿ってつながる場合などである。
輪郭線は、エッジの順序付きリスト、または曲線で表現される。曲線は輪郭線の数学的モデルである。曲線の例には、線分や3次スプラインなどがある。輪郭線を適切に表現するには、いくつかの基準がある:
輪郭表現の精度は、輪郭をモデル化するために使用される曲線の形状、曲線フィッティングアルゴリズムの性能、そしてエッジ位置の推定精度によって決まる。輪郭の最も単純な表現は、エッジの順序付きリストである。この表現はエッジの位置推定と同等の精度であるが、最も簡潔な表現ではないため、後続の画像解析に効果的な表現を提供できない可能性がある。適切な曲線モデルをエッジにフィッティングすると、平均化によってエッジ位置の誤差が低減されるため精度が向上し、後続の操作により適切かつ簡潔な表現を提供することで効率が向上する。例えば、直線に沿ったエッジの集合は、エッジに直線をフィッティングすることで最も効率的に表現できる。この表現は、直線の方向や長さの決定などの後続の計算を簡素化し、推定された直線と実際の直線との間の平均二乗誤差が、実際の直線と任意のエッジとの間の誤差よりも小さくなるため、精度が向上する。
この章の最初のセクションでは、平面曲線の初等微分幾何学について解説する。第2セクションでは、曲線モデルを辺に当てはめることなく、辺のリストから長さ、接線、曲率といった輪郭特性を計算する手法を紹介する。残りのセクションでは、曲線モデルと、そのモデルを輪郭に当てはめる手法について説明する。
先に進む前に、いくつかの用語を定義する必要がある。曲線は、点のリストを通過する場合、点のリストを補間する。近似とは、曲線が点の近くを通過するものの、必ずしも点を正確に通過するわけではない、点のリストに曲線をフィッティングすることです。以下のセクションでは、エッジ検出アルゴリズムによって提供されるエッジが正確であると仮定し、補間法を用いて曲線をエッジ点にフィッティングさせる。実際の画像にエッジ検出を適用して提供されるエッジは正確ではない。エッジの推定位置には多少の誤差が生じる。後のセクションでは、曲線近似の方法について説明する。
この章では、「エッジ」という用語は通常、エッジポイントを指す。エッジの方向は、ほとんどのカーブフィッティングアルゴリズムでは使用されない。アルゴリズムがエッジの方向を使用する少数のケースでは、「エッジ」という用語はエッジフラグメントを指していることが文脈から明らかになる。
平面曲線は、明示的な形式 \(y = f(x)\)、暗黙的な形式 \(f(x,y) = 0\)、あるいはパラメータ \(u\) に対するパラメトリック形式 \((x(u), y(u))\) の3つの方法で表現できる。明示的な形式は、マシンビジョンではほとんど使用されない。これは、\(Z-Y\)平面上の曲線がねじれることで、与えられた \(x\) に対して曲線上に複数の点が存在する可能性があるためである。
曲線のパラメトリック形式は、パラメータuの2つの関数 \(x(u)\) と \(y(u)\) を用いて、曲線の始点 \(p_1 = (x(u_1), y(u_1))\) から終点 \(p_2 = (x(u_2), y(u_2))\) までの曲線上の点を指定する。曲線の長さは円弧長で表される。 \[ \int_{u_1}^{u_2}\sqrt{\left(\frac{dx}{du}\right)^2+\left(\frac{dy}{du}\right)^2}du \tag{6.1} \] 単位接ベクトルは \[ \mathbf{t}(u)=\frac{\mathbf{p}^\prime(u)}{|\mathbf{p}^\prime(u)|} \tag{6.2} \] ここで \(\mathbf p(u)=\left(x(u),y(u)\right)\)。曲線の曲率は接線の微分:\(\mathbf n(u)=\mathbf p^{\prime\prime}(u)\)。
曲線上の3点、\(p(u+\Delta), p(u)\)、\(p(u-\Delta)\)を考えよう。これらの3点を通る円を想像してもらいたい。円はこれらの点によって一意に決定される。\(\Delta\to 0\) の極限において、この円は接触円である。接触円は曲線に \(p(u)\) で接し、円の中心は曲線の法線を含む直線上にある。曲率は接触円の半径の逆数である。
このセクションでは、輪郭線の長さ、接線の向き、曲率といった曲線形状の要素をエッジ点のリストから計算するための一連のアルゴリズムを紹介する。隣接するピクセル間の角度は45°単位に量子化されるため、傾きと曲率はデジタル領域で正確に計算することが困難である。
基本的な考え方は、エッジリスト内で隣接していないエッジ点を用いて接線方向を推定することである。これにより、可能な接線方向の集合がより広くなる。エッジリスト内のエッジ \(i\) の座標を \(\mathbf p_i = (x_i, y_i)\) とする。\(k\)-スロープは、\(k\) エッジ離れた点間の(角度)方向ベクトルである。左の \(k\)-スロープは、\(\mathbf{p}_{i-k}\) から \(\mathbf{p}_i\) への方向であり、右の \(k\)-スロープは、\(\mathbf{p}_i\) から \(\mathbf{p}_{i+k}\) への方向である。\(k\)-曲率は、左と右の \(k\)-スロープの差である。
エッジリストに \(n\) 個のエッジ点 \((x_1,y_1), ..., (x_n,y_n)\) があるとする。デジタル曲線の長さは、ピクセル間の個々の線分の長さを足し合わせることで近似できる。
\[
S=\sum_{i=2}^n\sqrt{(x_i-x_{i-1})^2+(y_i-y_{i-1})^2} \tag{6.3}
\]
エッジリストを走査し、辺に沿って2、対角線に沿って3を加え、最終的な合計を2で割ることで、良好な近似値が得られる。
(ここから蛇足) 重要ではないが気になったので...
・輪郭を辿って
水平または垂直に1ピクセル進んだら+2(後で2で割るので+1)
斜めに1ピクセル進んだら+3(後で2で割るので+1.5\(\approx\sqrt{2}\))
(途中の計算で実数演算したくないので2倍して整数化している)
だけの話だった...
(ここまで蛇足)
輪郭の端点間の距離は
\[
D=\sqrt{(y_n-y_1)^2+(x_n-x_1)^2} \tag{6.4}
\]
チェーンコードは、輪郭線に沿ったエッジポイントのリストを記録するための表記法である。チェーンコードは、エッジリスト内の各エッジにおける輪郭線の方向を指定するす。方向は、図6.1に示すように、8つの方向のいずれかに量子化される。リストの最初のエッジから始めて、輪郭線を時計回りに回り、次のエッジへの方向は、8つのチェーンコードのいずれかを使用して指定される。方向は、エッジの8次元のチェーンコードである。チェーンコードは、最初のエッジの座標と、後続のエッジにつながるチェーンコードのリストによってエッジリストを表す。曲線とそのチェーンコードを図6.2に示す。
\[ \begin{array}{|c|c|c|} \hline 2 & 3 & 4 \\ \hline 1 & \cdot & 5 \\ \hline 8 & 7 & 6 \\ \hline \end{array} \]
チェーンコードには、魅力的な特性がある。物体を 45° 回転させる処理は簡単に実装できる。物体を n×45° 回転させると、回転後の物体のコードは元のコードに n mod 8 を加算することで得られる。チェーンコードの導関数 (差分コードとも呼ばれる) は、第一差分を使用して得られ、回転不変の境界記述である。領域の面積や角などの他の特性も、チェーンコードを使用して直接計算できる。この表現の制限は、ある点における接線を表現するのに使用される方向のセットが限られていることである。この制限は、次のセクションで説明する曲線表現のいずれかを使用することで解消できる。曲線をエッジのリストにフィッティングすると、セクション 6.1 で示した幾何学的量はすべて、曲線の数式から計算できる。
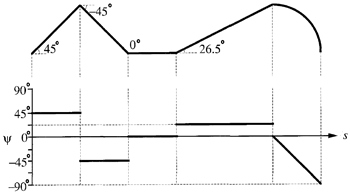
輪郭の傾きの表現は \(\Psi-s\) プロットとも呼ばれ、チェーンコードの連続バージョンのようなものである。チェーンコードで許可されている限られた接線方向ではなく、任意の接線方向を使用して輪郭を表現する。エッジリストの先頭から始めて、デジタル曲線の式を使用して接線と円弧長を計算するものとする。接線 \(\Psi\) と円弧長 \(s\) をプロットして、\(\Psi-s\) 空間での輪郭の表現を取得する。\(\Psi-s\) プロットは、輪郭の形状の表現である。たとえば、線分と円弧で構成される輪郭は、\(\Psi-s\) プロットでは線分の連続のように見える。\(\Psi-s\) プロットの水平線分は、輪郭の線分に対応する。 \(\Psi-s\) プロット内の他の方向の線分は円弧に対応する。\(\Psi-s\) プロット内の直線ではない部分は、他の曲線プリミティブに対応する。
\(\Psi-s\) プロットを直線に分割することで、輪郭を直線と円弧に分割することができる。この手法は多くの研究者によって使用されており、輪郭を線分に分割するこの手法にはいくつかのバージョンがある。
\(\Psi-s\) プロットは、元の輪郭の形状を簡潔に記述するために使用できる。図6.3は、輪郭とその \(\Psi-s\) プロットを示している。閉じた輪郭の場合、\(\Psi-s\) プロットは周期的である。
傾斜密度関数は、輪郭に沿った傾斜(接線角)のヒストグラムである。これは認識のための有用な記述子となり得る。モデル輪郭の傾斜密度関数と画像から抽出した輪郭の傾斜密度関数を相関させることで、物体の向きを特定することができる。これは物体認識の手段にもなる。
この章の残りの部分では、4つの曲線モデルと、それらをエッジ点にフィッティングする手法について説明する。これらのモデルには以下のものがある。
あらゆるフィッティングアルゴリズムは、次の2つの質問に答える必要がある。
セクション6.4から6.7では、エッジの位置が十分に正確であり、選択されたエッジ点を用いてフィッティングを決定できるという仮定のもと、曲線モデルをエッジにフィッティングする手法について説明する。セクション6.8では、エッジの位置の誤差を処理できる、より強力な手法を順に紹介する。
\(d_i\) を、直線からエッジ点 \(i\) までの距離とする。曲線と候補エッジ点の適合度を測る尺度はいくつかある。いずれも、適合曲線と曲線を形成する候補点との間の誤差に依存する。以下に、一般的に用いられる手法をいくつか示す。
正規化された最大誤差は、曲線の長さに依存しない単位のない誤差の尺度となる。言い換えれば、ある曲線からの所定の偏差は、用途によっては、長さが2倍の曲線からの偏差が2倍であることと同等に重要な場合がある。曲線モデルが線分である場合、円弧の長さを計算する必要はない。端点間の距離Dを使用できる。 \[ D= \sqrt{(y_n-y1)^2+(x_n-x_1)^2} \tag{6.8} \]
符号の変化は、適合度を示す非常に有用な指標である。エッジ点のリストを直線で近似し、符号の変化の数を調べる。符号の変化が1つであれば、エッジのリストは直線でモデル化できる可能性があり、符号の変化が2つであれば、エッジは2次曲線でモデル化すべきであり、符号の変化が3つであれば、3次曲線でモデル化すべきであることを示す。符号の変化が多数ある場合、曲線の複雑さが少し増加しても適合度は大幅に改善されないことを示す。良好な適合度は、符号の変化にランダムなパターンを示す。同じ符号の誤差が連続して発生する場合、適合度に系統的な誤差があることを示す。これは、おそらく曲線モデルが間違っていることが原因である。
以降の節では、単純な曲線フィッティング法を用いて、折れ線、円弧、円錐曲線、3次スプラインの各モデルの使用方法を説明する。6.8節では、折れ線を主な例として、より強力な曲線フィッティング法を紹介する。ただし、原理的には、以降の節で紹介するモデルはいずれも、6.8節で紹介するどの曲線フィッティング法とも併用できる。
曲線フィッティングモデルの選択は、アプリケーションによって決まる。シーンが直線で構成され、他のモデルのフィッティングの開始点となる場合は、線分(折れ線)の使用が適切である。円弧は、曲線が曲率が区分的に一定であるセクションに分割されるため、曲率を推定するのに便利な表現方法である。円錐曲線は、線分と円弧、楕円弧、双曲弧のシーケンスを表現する便利な方法を提供し、変曲点を明示的に表現する。3次スプラインは滑らかな曲線をモデル化するのに適しており、接線ベクトルと曲率の推定値が区分的に一定である必要はない。
折れ線とは、端と端を繋いだ線分の列である。輪郭線の折れ線表現は、線分の列でエッジリストを近似する。折れ線は、エッジリスト内の選択されたエッジ点のサブセットを補間する。各線分の端は、元のエッジリスト内のエッジ点である。各線分は、その端点間の連続する曲線の連なりをモデル化する。線分が繋がっている点は頂点と呼ばれる。折れ線は、この章で説明するすべての曲線と同様に、画像平面上の2次元曲線であり、頂点は画像平面上の点であることに注意。
折れ線アルゴリズムは、エッジポイントの順序付きリスト\(\{(x_1, y_1), (x_2, y_2), ..,(x_n, y_n)\}\)を入力として受け取る。エッジポイントの座標はサブピクセル解像度で計算できる(セクション5.7を参照)。線分は頂点として選択された2つのエッジポイント間に適合されるため、頂点として選択されたエッジの座標のみを正確に計算する必要がある。
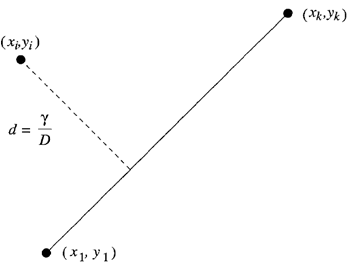
図6.4: 線分から点までの垂線距離を示す図。値 \(\gamma\) は、点の座標 \((x_i, y_i)\) を線分の式に代入することで計算される。
端点のリストを近似し、最初の端点と最後の端点 \((x_1,y_1)\) と \((x_k,y_k)\) を結ぶ線分の式は、端点間の直線の傾きが、最初の点と直線上の任意の点間の直線の傾きと同じであることに注目することで導き出せる。 \[ \frac{y-y_1}{x-x_1}=\frac{y_k-y_1}{x_k-x_1} \tag{6.9} \] 項を掛け合わせて並べ替えると、端点の座標でパラメータ化された線分の暗黙的な形が得られる。 \[ x(y_1-y_k)+y(x_k-x_1)+y_kx_1-y_1x_k= 0 \tag{6.10} \] 任意の点\((x_i,y_i)\)から直線までの距離は\(d = r/D\)である。ここで\(r\)は、点の座標を線分の式に代入することで計算される。 \[ r=x_i(y_1-y_k)+y_i(x_k-x_1)+y_kx_1-y_1x_k \tag{6.11} \] \(D\)は端点間の距離である(図6.4参照)。\(r\) の符号は符号変化回数 \(C\) を計算するために使用できる。正規化された距離は \(d/D\) である。正規化された最大絶対誤差は \(d/D\) である。 \[ \varepsilon=\frac{\max_i |d_i|}{D} \tag{6.12} \] ここで、\(d_i\) は直線とエッジリストの \(i\) 番目のエッジの位置との間の距離である。正規化された最大誤差は、直線とエッジの集合との適合度の尺度として頻繁に用いられる。これらの式はすべて、点の直線への垂直投影が直線内、つまり直線上と直線の端点間にあることを仮定している。これは本章全体を通して当てはまるが、他の場合には、線分の最も近い端点から点までの距離を計算するために式を修正する必要があるかもしれない。
折れ線をフィッティングする方法には、トップダウン分割とボトムアップ結合の2つがある。
トップダウン分割アルゴリズムは、初期曲線から始めて、頂点を再帰的に追加する。図 6.5 に示す曲線を考えてみよう。初期曲線は、A と B でラベル付けされた最初のエッジ ポイントと最後のエッジ ポイント間の線分である。エッジ リスト内で直線から最も遠い点が検索される。正規化された最大誤差がしきい値を超える場合、線分から最も遠いエッジ ポイント (図 6.5 の点 C) に頂点が挿入される。分割アルゴリズムは、2 つの新しい線分とエッジ リストに再帰的に適用される。エッジ リストは、2 つの線分に対応する 2 つのリストに分割される。リスト内で各線分から最も遠いエッジ ポイントが検索され、ポイントが線分から離れすぎている場合は新しい頂点が追加される。折れ線分割アルゴリズムは、折れ線上のすべてのエッジ ポイントの正規化された最大誤差がしきい値を下回ると終了する。この再帰的な手順は非常に効率的である。セグメント分割は再帰的細分化とも呼ばれる。
セグメント併合では、エッジリストを走査するにつれて、エッジポイントが線分に追加される。エッジポイントが線分から大きく外れると、新しい線分が開始される。併合アプローチは、折れ線フィッティングのボトムアップアプローチとも呼ばれる。
エッジ点が形成中の線分から離れすぎているかどうかを判断するために使用できる手段はいくつかある。1つの方法は、逐次最小二乗法を使用することである。これは、線分をエッジ点に最小二乗近似し、新しいエッジ点が処理されるたびに線分のパラメータを段階的に更新する。この近似アルゴリズムは、線分とエッジ点の間の残差の二乗を計算する。誤差が閾値を超えると、頂点が導入され、最後の線分の終点から新しい線分が開始される。
許容帯域アルゴリズムは、頂点の配置を決定するために異なる方法を使用する。中心線分から \(\epsilon\) の距離にあるエッジポイントを近似する線分に平行な2つの線分が計算される(図6.6を参照)。\(\epsilon\) の値は、近似直線からの許容される絶対偏差量を表す。新しいエッジは、許容帯域内にある限り、現在の線分に追加される。新しいエッジが線分に追加されるたびに、線分のパラメータが再計算される場合がある。近似線分は、許容帯域の辺に平行である必要はない。線分の端にある頂点は、次の線分の始点となる。このアプローチでは、通常、線分が多くなりすぎる。アルゴリズムが許容帯域の境界までエッジを処理するまで頂点が作成されないため、コーナーの位置と角度は正確に推定されない。
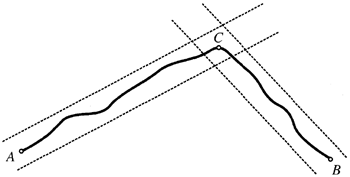
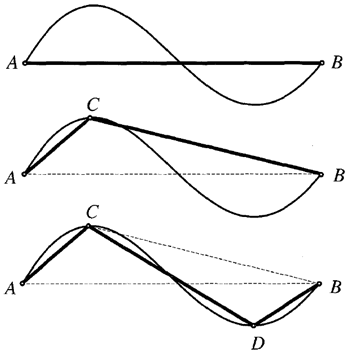
トップダウンの再帰的細分化法とボトムアップの併合法は、分割・併合アルゴリズムとして組み合わせることができる。分割・併合法は単独で使用した場合、部分的にしか効果がないが、併合と分割操作を交互に行うことで、エッジリストに対する線分近似の精度を向上させることができる。図6.7は、分割とその後に併合を行うことで、不適切に配置されていた頂点を修復できる例を示している。
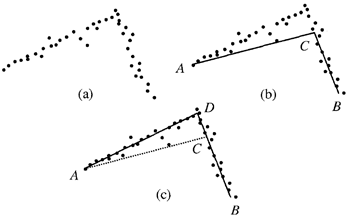
図6.7: ボトムアップのエッジ併合によって生成された、真のコーナー位置を逃した不適切なコーナー推定は、分割パスと併合パスによって修復できる。分割パスと併合パスは、最初のセグメントを真のコーナーに近い点で分割し、2つのセグメントを1つの線分に併合する。
基本的な考え方は、分割パスと併合パスを交互に実行することである。再帰的な細分化の後、新しい線分がより少ない正規化誤差でエッジに適合する場合、隣接する線分を最初の端点と最後の端点の間の単一の線分に置き換えることを許可する。複数の線分は常に、単一の線分よりも少ない誤差でエッジのリストに適合するため、正規化誤差を使用する必要があることに注意。線分の併合後、新しい線分は異なる点で分割される場合がある。分割と併合を交互に適用し、線分が併合または分割されなくなるまで続ける。
ホップアロングアルゴリズムは、上述の分割・併合法と同様に、線分のシーケンスによって輪郭を近似するが、短いエッジのサブリストに対して機能する。アルゴリズムは、エッジポイントのリストの一方の端から開始し、一定数のエッジを取得し、最初のエッジポイントと最後のエッジポイントの間に線分を当てはめる。適合度が悪かった場合、アルゴリズムは最大誤差の点で分割し、実行の開始点に最も近いポイントで繰り返す。言い換えると、アルゴリズムは、初期のエッジシーケンスに適した線分近似が見つかるまでフォールバックする。アルゴリズムは、現在のセグメントを前のセグメントとし、残りのエッジポイントで処理を続ける。また、アルゴリズムは、現在のセグメントを前のセグメントと併合できるかどうかも確認する。このアルゴリズムは分割・併合アルゴリズムに似ているが、エッジのリスト全体から開始せず、多くの分割を行う時間を無駄にしない。このアルゴリズムは、適度な大きさのエッジの連続をホップしながら処理する。このアルゴリズムはアルゴリズム6.1として示されている。
アルゴリズム 6.1 折れ線フィッティングのためのホップアロングアルゴリズム
このアルゴリズムは、エッジのウィンドウを定数 \(k\) だけ進めながらホップする。線分のエッジへの適合が不十分な場合、アルゴリズムは最大誤差の点に戻る。このアルゴリズムは短いエッジ列のみを考慮するため、純粋な再帰的細分化や分割・併合アルゴリズムよりも効率的である。これらのアルゴリズムは、エッジのリスト全体から開始し、エッジリストを管理しやすい部分に分割するのに多くの時間を浪費する。
エッジのリストを線分で近似した後、必要に応じて線分のサブシーケンスを円弧に置き換えることができる。線分を円弧に置き換えるには、2つ以上の線分の端点を通る円弧をフィッティングする必要がある。言い換えれば、円弧のフィッティングは折れ線の頂点上で行われる。輪郭線を線分と円弧のシーケンスとして表すと、輪郭線は点ごとに一定の曲率を持つセクションに分割される。多くの画像解析アルゴリズムは曲率情報を使用する。
2点間の線分の暗黙の公式を導出したのと同様に、3点を通る円の暗黙の公式を導出する必要がある。半径\(r\)、中心\((x_0,y_0)\)の円の暗黙の方程式は、 \[ (x-x_0)^2+(y-y_0)^2=r-2 \tag{6.13} \] 3点\(\mathbf p_1 = (x_1,y_1), \mathbf p_2 = (x_2,y_)\)、\(\mathbf p_3 = (x_3,y_3)\)を考える。座標系の原点を点pに変換する。新しい座標系では、 \[ \begin{align} x^\prime &= x - x_1 \tag{6.14} \\ y^\prime &= y - y_1 \tag{6.15} \end{align} \] そして円の方程式は \[ (x^\prime - x_0^\prime)-2+(y^\prime - y_0^\prime)^2 = r^2 \tag{6.16} \] 円の暗黙方程式の点 \(p_1, p_2\)、\(p_3\) を \(x^\prime-y^\prime\) 空間の座標に代入する。 \[ \begin{align} {x_0^\prime}^2+{y_0^\prime}^2-r^2 &=0 \tag{6.17} \\ \\ {x_2^\prime}^2-2x_2^\prime x_0^\prime+{x_0^\prime}^2+{y_2^\prime}^2-2y_2^\prime y_0^\prime+{y_0^\prime}^2-r^2 &= 0 \tag{6.18} \\ \\ {x_3^\prime}^2-2x_3^\prime x_0^\prime+{x_0^\prime}^2+{y_3^\prime}^2-2y_3^\prime y_0^\prime+{y_0^\prime}^2-r^2 &= 0 \tag{6.19} \end{align} \] これにより、3 つの未知数 \(x_0^\prime、y_0^\prime\)、および \(r\) に対する 3 つの非線形方程式が生成される。
最初の方程式から 2 番目と 3 番目の方程式を引く。 \[ \begin{align} 2x_2^\prime x_0^\prime+2y_2^\prime y_0^\prime &= {x_2^\prime}^2+{y_2^\prime}^2 \tag{6.20} \\ \\ 2x_3^\prime x_0^\prime+2y_3^\prime y_0^\prime &= {x_3^\prime}^2+{y_3^\prime}^2 \tag{6.21} \end{align} \] これにより、2つの未知数 \(x_0^\prime\) と \(y_0^\prime\) に関する2つの線形方程式が得られる。これらは、\(x^\prime - y^\prime\) 空間における円の中心の座標である。\((x_1, y_1)\) を \((x_0^\prime, y_0^\prime)\) に加えると、元の座標系における円の中心が得られる。円の半径は \(r^2 = {x_0^\prime}^2+{y_0^\prime}^2\) から計算する。
円弧のフィッティング誤差を計算するには、点\(Q\)から円までの距離を、円の中心を通る直線に沿った点\(Q\)から円までの距離と定義する。円の半径を\(r\)とする。点\(Q\)から円の中心\((x_0,y_0)\)までの座標\((x_i, y_i)\)からの距離\(q\)を計算する。 \[ q = \sqrt{(x_i - x_0)^2+(y_i - y_0)^2} \tag{6.22} \] 点\(Q\)から円弧までの距離は \[ d=q-r \tag{6.23} \]
3点に円弧を当てはめる公式が得られたので、次は適合度を評価する方法が必要である。円弧が線分よりもエッジに近似しているかどうかを判断できるからである。輪郭線の長さと、最初の端点と最後の端点間の距離の比が閾値より大きい場合、線分を円弧に置き換えることができるかもしれない。円弧は、最初の端点と最後の端点、そしてもう1点の間に当てはめられる。円弧を折れ線のシーケンスに当てはめる方法はいくつかあり、中心点の選び方によって次のように異なる。
すべてのエッジ点と円弧との間の符号付き距離を計算する。 最大絶対誤差と符号変化回数を計算する。正規化された最大誤差が閾値を下回り、符号変化回数が大きい場合は円弧を受け入れる。それ以外の場合は、折れ線近似を維持する。線分を円弧に置き換えるアルゴリズムは、アルゴリズム6.2に概説されている。
アルゴリズム 6.2 線分を円弧に置き換える
折れ線に対してアルゴリズム6.2を実行すると、輪郭線は線分と円弧の連続によって表現される。表現に2つの異なる曲線プリミティブが含まれるのは不便かもしれない。次のセクションでは、線分、円弧、その他のプリミティブを同じ表現で共存させることができる円錐曲線について説明する。円錐曲線は、必要に応じて断面間の滑らかな遷移を提供し、コーナーを明示的に表現することもできる。
このセクションでは、端点のリストを円錐曲線で近似する方法について説明する。円弧の場合と同様に、この方法では、まず端点が折れ線で近似され、線分のサブシーケンスが円錐曲線に置き換えられると仮定する。
双曲線の暗黙的(代数的)形式は \[ f(x,y)=ax^2+2hxy+by^2+2ex+2gy+c= 0 \tag{6.24} \] 円錐曲線には、双曲線、放物線、楕円の3種類がある。円は楕円の特殊な例である。幾何学的には、円錐曲線は図6.8に示すように、円錐と平面の交差によって定義される。
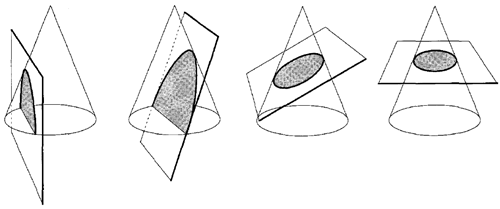
円錐曲線は、輪郭への折れ線近似において、3つの頂点間にフィットさせることができる。円錐曲線が結合されている箇所はノットと呼ばれる。円錐スプラインは、ノットにおける接線が等しく、曲線の隣接するセクション間の滑らかな遷移を実現する、端と端を繋いだ円錐曲線の列である。折れ線の頂点を \(V_i\) とする。円錐曲線近似は図6.9に示されている。
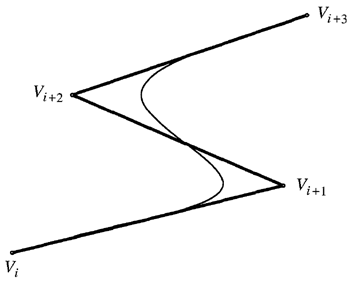
円錐スプラインの各円錐曲線は、2つの端点、2つの接線、および1つの追加点によって定義される。ノット \(K_i\) は、折れ線の頂点間に配置できる。 \[ K_i=(1-\nu_i)V_i+\nu_iV_{i+1} \tag{6.25} \] ここで\(\nu_i\)は0と1の間である。接線は、頂点\(V_i, V_{i+1}\)、\(V_{i+2}\)を持つ三角形によって定義される。追加の点は図6.10に示すように以下となる。 \[ Z_i=\gamma_i V_{i+1}+(1-\gamma_i)\frac{K_i+K_{i+1}}{2} \tag{6.26} \]
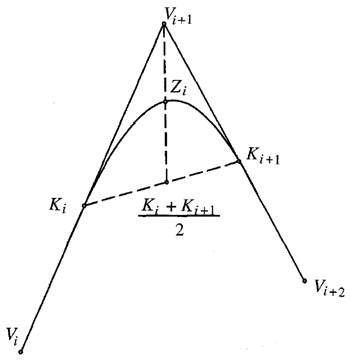
図6.10: 円錐曲線は、折れ線近似の3つの頂点から得られる2つの端点と接線、および1つの追加点によって定義される。
この表現によって統一的に扱える円錐曲線の特殊なケースがいくつかある。\(\nu_{i+1}= 0\) の場合、円錐スプラインの \(i\) 番目の断面は \(K_i\) から \(V_{i+1}\) までの線分である。\(\nu_i = 1\) かつ \(\nu_{i+1}= 0\) の場合、\(K_i, K_{i+1}\)、および \(V_{i+1}\) は同じ点に収束し、円錐曲線の列にコーナーが存在する。これらの特殊な特性により、異なるプリミティブや特殊なフラグに頼ることなく、円錐スプラインで線分とコーナーを明示的に表現できる。
ここで提示する円錐スプラインを計算するアルゴリズムは、円錐曲線のガイド形式を使用する。これは、3つの線で円錐曲線を表す。 円錐曲線の境界を定めた。(図6.11を参照)直線の方程式は \[ a_0 + a_1x + a_2y = 0 \tag{6.27} \]
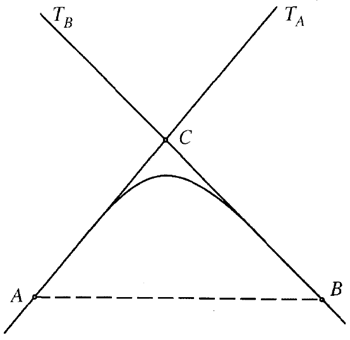
折れ線の最初と最後の頂点をそれぞれ \(A\) と \(B\) とし、点 \(C\) を折れ線の中間の頂点とする。最初と最後の頂点は弦 \(AB\) で結ばれている。円錐曲線の有向形は、端点が \(A\) と \(B\) で、接線 \(AC\) と \(BC\) が次の式で定義される円錐曲線の族である。 \[ (a_0 + a_1x + a_2y) (b_0 + b_1x + b_2y) = \rho(u_0+u_1x+u_2y)^2 \tag{6.28} \] ここで \[ a_0+a_1x + a_2y = 0 \tag{6.29} \] は、線分\(AC\)を含む線分であり、 \[ b_0 + b_1x + b_2y =0 \tag{6.30} \] は、線分\(BC\)を含む直線であり、 \[ u_0+u_1x+u_2y =0 \tag{6.31} \] は、弦\(AB\)を含む直線である。円錐曲線族は\(\rho\)によってパラメータ化される。
円錐曲線をエッジ点のリストに当てはめるアルゴリズムは、折れ線から始まり、頂点をコーナー、ソフト頂点、またはノットに分類する。ソフト頂点は角度が \(180°\) に近い値を持ち、隣接する線分はほぼ同一直線上にあるため、円錐曲線に置き換えることができる。ソフト頂点のシーケンスは、滑らかな曲線に沿ってサンプリングされたエッジ点に当てはめられた可能性が高い、方向が徐々に変化する線分のシーケンスに対応する。コーナーは、頂点角度が \(180° + T_1\) を超えるか \(180°-T_1\) を下回る (\(T_1\) は閾値)。そのため、円錐曲線の一部である可能性は低くなる。ノットは、両端に反対方向に角度が付いたソフト頂点を持つ線分に沿って配置される。円錐曲線は屈曲点を持たないため、2つの円錐曲線は結び目で繋がる必要がある。線分に沿った結び目の配置は、線分の両端のソフト頂点の相対的な角度によって決まる。2つのソフト頂点 \(V_i\) と \(V_{i+1}\) の角度をそれぞれ \(A_i\) と \(A_{i+1}\) とする。\(A_i = A_{i+1}\) の場合、結び目は頂点間の中間に配置される。これは、式 6.25 において \(\nu = 1/2\) を意味する。角度が同じでない場合、円錐曲線が線分から十分に速く曲がらず、角をたどらない可能性があるため、結び目の位置は角度の大きい頂点から離れた位置にする必要がある。式6.25のvの値は、次の式で設定できる。 \[ \nu_i=\frac{A_1}{A_1+A_2} \tag{6.32} \]
ソフト頂点で結ばれた線分のシーケンスはそれぞれ、最初と最後の頂点(またはノット)を通る誘導円錐曲線に置き換えられる。接線は、最初と最後の線分の方向によって定義される。接線と端点は、円錐曲線の5つの自由度のうち4つを決定する。円錐曲線は、シーケンスの途中にあるソフト頂点を通過することで完全に指定される。
スプラインという用語は、区分多項式を用いて表現される関数を指す。 スプラインは多くの応用分野で用いられる。データ解析においては、関数モデルが利用できない場合に、スプラインはデータ点の集合を近似するために使用される[245]。コンピュータグラフィックスやコンピュータ支援設計においては、スプラインは自由曲線を表現するために使用される。マシンビジョンにおいては、より単純なモデルが適切でない場合に、スプラインは曲線の汎用的な表現を提供する。
スプラインは、任意のクラスの関数を端から端まで結合することで作成できる。 最も一般的なスプラインの形式は3次スプラインで、区分3次多項式の列である。前のセクションで示した線分、円弧、円錐曲線などの曲線表現もスプラインの例である。3次スプラインを使用すると、より複雑な曲線をより少ないスプラインセグメントで表現できる。3次スプラインは、コンピュータ描画プログラムで周波数曲線やフォントの文字アウトラインを表現するために広く使用されている。3次スプラインは広く使用されているため、マシンビジョンプログラムでは、この曲線モデルをエッジリストに適合させる必要がある場合がある。3次スプライン曲線を操作するための対話型グラフィックスインターフェースは広く知られているため、3次スプラインとして表現された輪郭は、必要に応じてユーザーが手動で変更できる。これは非常に重要な考慮事項である。なぜなら、曲線をエッジに適合させた結果が完璧になることは決してないからである。
明確にしておきたい点の一つは、幾何学的等価性とパラメトリック等価性の違いである。2つの曲線が同じ点集合を辿る場合、それらの曲線は幾何学的に等価である。言い換えれば、2つの曲線は空間内の同じ形状(または点集合)に対応する場合、幾何学的に等価である。2つの曲線は、方程式が同一である場合、パラメトリック等価である。言い換えれば、2つの曲線の表現が同じパラメータを持つ同じ式である場合、それらの曲線はパラメトリック等価である。パラメトリック等価性は幾何学的等価性よりも強い。
2つの曲線は幾何学的には等価であっても、パラメトリック表現が異なることがある。これは、マシンビジョンにおける曲線フィッティングにおいて重要な概念である。マシンビジョンシステムは、物体境界の真の表現に(幾何学的には)非常に近い3次スプラインに基づく表現を生成するかもしれないが、その表現はパラメトリック感覚では全く類似していない可能性がある。物体認識や工業部品の画像とそのモデルの比較などのアプリケーションでは、3次スプライン曲線のパラメトリック形式を比較することはできない。比較は幾何学的等価性に基づいて行う必要がある。
3次スプラインは、エッジ断片の方向を近似に用いるのに十分な自由度を持っている。ほとんどのエッジ検出アルゴリズムは、エッジの位置だけでなく、エッジの方向(勾配角)の推定値も提供できることを思い出してもらいたい。線分、円弧、円錐曲線のフィッティングアルゴリズムでは、エッジの位置のみが使用されていた。3次スプラインを用いて、エッジ検出器によって生成された方向情報の使用方法の例を紹介しよう。平面上の3次曲線の方程式は、 \[ \mathbf p(u) = (x(u), y(u)) = \mathbf a_0 + \mathbf a_1u+\mathbf a_2u^2+\mathbf a_3u^3 \tag{6.33} \] ここで、係数 \(a_0, a_1, a_2\)、\(a_3\) は2要素ベクトル(画像平面上の点)であり、パラメータ \(u\) は区間 \([0,1]\) をカバーする。3次曲線は点 \(\mathbf p(0) = (x(0), y(0))\) で始まり、点 \(\mathbf p(1) = (x(1), y(1))\) で終わる。 3次スプラインは、連続する区間 \([0,1], [1,2],...,[n-1,n]\) 上で定義され、端点で \(\mathbf p_i(i) = \mathbf p_{i+1}(i)\) となるように結合された3次曲線の列 \(\mathbf p_1(u), \mathbf p_2(u),...,\mathbf p_n(u)\) である。スプライン内の各3次曲線はスプライン線分と呼ばれ、線分が結合される端点は結び目(節点, ノット)と呼ばれる。
前のセクションで説明した曲線フィッティングアルゴリズムと同様に、エッジ点のシーケンスはサブシーケンスに分割され、各サブシーケンスにスプラインセグメントがフィッティングされる。スプラインの各3次曲線セグメントには、8つのパラメータが必要である。サブシーケンスの最初と最後のエッジ点の位置は、4つの制約条件を提供する。ノットにおける1次連続性(等しい接線ベクトル)は、さらに2つの制約条件を提供する。ノットにおけるエッジの方向は、隣接するセグメントによってエッジが共有されるため、各セグメントに1つの追加制約条件のみを提供する。ノットにおける2次連続性(等しい曲率)は、さらに2つの制約条件を提供するが、そうすると、各3次スプラインセグメントの8つのパラメータに対する方程式が多すぎる。
スプライン線分がノットで滑らかに接続されることが重要であり、コンピュータグラフィックスでは、2次連続性を必須とすることでこれを実現する。2次連続性を必須とすると、各スプライン線分は既にエッジの方向によって方向(接線角)が制約された状態で選択されたエッジを通過するように制約されているため、過剰な制約となる。しかし、ノットにおける2次不連続性の大きさを最小化することで、さらにもう1つの制約を与えることができる。言い換えれば、ノットにおける曲率の差を最小化するということである。
3次スプライン曲線全体について、\(n-1\)ノットにおける2次導関数の差の2乗の合計を最小化する。 \[ \chi^2=\sum_{i=1}^{n-1}(\Delta\ddot{\mathbf p}) \tag{6.34} \] ここで、2つのスプラインセグメントの共通節点における2次導関数の差は \[ \begin{align} \Delta\ddot{\mathbf p} &= \ddot{\mathbf p}_{i-1}(1)-\ddot{\mathbf p}_i(0) \tag{6.35} \\ \\ &=2\left(\mathbf t_{i-1}+4\mathbf t_i+\mathbf t_{i+1}+3(\mathbf p_{i-1}-\mathbf p_i)\right) \tag{6.36} \end{align} \] 変数\(\mathbf t_i\)は、節点\(i\)における接線ベクトルである。接線ベクトルの向き\(\hat{\mathbf t}_i\)は、エッジの向き(勾配角)によって与えられ、大きさ\(\gamma_i\)は未知である。 \[ \mathbf t_i = \gamma_i\hat{\mathbf t}_i \tag{6.37} \] 言い換えれば、結び目におけるエッジの向きは単位接線ベクトルとしてモデル化されるが、3次スプラインでは、曲線がどの方向からどの速度で結び目を通過するかを示すために、符号と大きさを持つ接線が必要である。このアルゴリズムは、節点間の3次スプライン線分を構築するために必要な情報を提供する \(n\) 個の未知数\(\gamma_i\)について、連立一次方程式を解く。
このアルゴリズムには追加のパラメータや閾値はないが、前のセクションで紹介した折れ線、円弧、円錐曲線のフィッティングアルゴリズムと同様に、節点はエッジリストから選択する必要がある。節点トの位置は、輪郭線の折れ線近似を計算するために上記で説明した折れ線アルゴリズムのいずれかを使用して決定できる。折れ線の頂点は節点の位置として使用できる。節点の数と配置を調整することで、3次スプラインのエッジ点全体へのフィッティングを向上させることができる。
3次スプラインフィッティングアルゴリズムは非常に効率的である。解を求めるには、接線と正弦波、振幅を求める小さな連立一次方程式を解くだけで済む。必要に応じて、ユーザーが3次スプライン曲線を簡単に調整できる対話型グラフィックインターフェースが数多く存在する。
前のセクションで説明した曲線フィッティング手法では、曲線をエッジの部分集合を通して補間していた。特定のエッジを通過させない近似値を計算すると、より高い精度が得られる。
この節では、曲線を近似する方法を紹介する。曲線を近似する方法はいくつかあり、エッジ点を輪郭にグループ化できる信頼性によって異なる。輪郭に連結されたすべてのエッジ点が実際にその輪郭に属していることが確実な場合は、全最小二乗回帰法を使用してエッジ点に曲線を当てはめることができる。グループ化に誤差がある場合は、ロバスト回帰法を使用して曲線近似を計算できます。最後に、エッジを輪郭にグループ化する信頼性が非常に低い場合、またはエッジが散在しているために前述のエッジ連結法やそれに続く方法を使用して簡単にグループ化できない場合は、クラスター分析手法を使用してグループ化と曲線フィッティングを同時に実行する必要がある。散在するエッジ点をグループ化してフィッティングするアルゴリズムの優れた例として、ハフ変換がある。これらの方法については、以降の節で説明する。
セクション 6.4 から 6.7 で紹介した、線分、円弧、円錐曲線、および 3 次スプラインをエッジ点にフィッティングする方法は、端点間の曲線セグメントをフィッティングする単純な回帰問題である。これらのアルゴリズムは、エッジの位置がサブピクセル法などを用いて正確に計算できることを前提としている。端点間のエッジ点は回帰では使用されない。曲線近似の精度は、セグメントの端点として選択されたエッジ点の位置の精度によって決まる。このセクションで紹介する方法では、すべてのエッジ点を使用して、エッジ点に対する曲線の最良近似を計算する。
一般的な曲線フィッティング問題は、曲線を暗黙方程式でモデル化した回帰問題である。 \[ f(x,y;a_1,a_2,\cdots,a_p)=0 \tag{6.38} \] \(p\) 個のパラメータを持つ。 曲線推定問題は、曲線モデルをエッジ点の集合 \(\{(x_1, y_1), (x_2, y_2), \cdots,(x_n, y_n)\}\) に適合させることである。
ノイズがない場合、\(p\) 個の観測値を用いて \(p\) 個の未知の曲線パラメータに対する\(p\) 個の方程式を定式化できる。残念ながら、ほとんどのアプリケーションでは、ノイズのためにこの直接的なアプローチは適切ではない。実際のアプリケーションでは通常、エッジリスト内のすべての情報を用いてパラメータ値の最良の推定値を求める必要がある。
次のセクションでは、マシンビジョンにおける曲線フィッティングに用いられる最小二乗回帰について説明する。最小二乗法は、誤差が正規分布する場合に適している。セクション6.8.3では、エッジ点の一部が誤って輪郭線にリンクされている場合に有効な、堅牢な曲線フィッティング手法を紹介する。これらの誤ってリンクされた点は外れ値と呼ばれる。
古典的な線形回帰は、データポイントとモデルの差を、従属変数の次元のみで最小化する。例えば、次のような関数モデルは、 \[ y=f(x,a_1,\cdots,a_p) \tag{6.39} \] 従属変数 \(y\) を独立変数 \(x\) に、\(p\) モデルパラメータ \(a_1\) から \(a_p\) までを用いて関連付ける場合、独立変数 \(x\) には誤差がないものと仮定する。マシンビジョンでは、位置座標 \(x\) と \(y\) の誤差は等確率で発生し、曲線モデルは例えば関数形式では表現できない垂直線になることがある。マシンビジョンでは、直線やその他の曲線モデルは、回帰モデルからのデータポイントの垂直距離の二乗和を最小化する全回帰を用いてエッジにフィッティングされる。この手法の利点は、\(x\) 方向と \(y\) 方向の両方の誤差を補正できることである。全回帰は実際には既に第2章で紹介されており、ブロブの方向を決定するための式を導くために使用されていましたが、その時は「全回帰」という用語は使用していなかった。
直線が垂直な場合の問題を回避するには、直線の方程式を極座標を使用して表す。 \[ x\cos\theta+y\sin\theta^\rho = 0 \tag{6.40} \] 直線からの点 \((x_i,y_i)\) の垂直距離の二乗の合計を最小化する。 \[ \chi^2=\sum_i (x_i\cos\theta+y_i\sin\theta-\rho)^2 \tag{6.41} \] 全回帰問題の解は \[ \rho = \overline{x}\cos\theta+\overline{y}\sin\theta \tag{6.42} \] ここで \[ \begin{align} \overline{x} &=\frac{1}{n}\sum_{i=1}^n x_i \tag{6.43} \\ \\ \overline{y} &=\frac{1}{n}\sum_{i=1}^n y_i \tag{6.44} \end{align} \] 全回帰直線の方向は\(\theta\)で、次のように表される。 \[ \tan 2\theta=\frac{a}{b} \tag{6.45} \] ここで \[ \begin{align} a &= 2\sum_{i=1}^n x_i^\prime y_i^\prime \tag{6.46} \\ \\ b &= \sum_{i=1}^n {x_i^\prime}^2-\sum_{i=1}^n{y_i^\prime}^2 \tag{6.47} \end{align} \] および \[ \begin{align} x_i^\prime &= x_i - \overline{x} \tag{6.48} \\ \\ y_i^\prime &= y_i - \overline{y} \tag{6.49} \end{align} \]
全回帰では、誤差が正規分布に従う場合には最適な最小二乗誤差ノルムを使用するが、データに外れ値が存在する場合には適していない。曲線モデルをエッジデータにフィッティングする場合、エッジリンク手順によって、他の輪郭線から1つ以上のエッジが輪郭線のエッジリストに組み込まれると、外れ値が発生する。エッジリンク手順が完璧に実行されたとしても、外れ値が発生する可能性がある。例えば、矩形の隣接する2辺のエッジのリストを考えてみよう。エッジに線をフィッティングする前に、エッジを2辺に分割するためには、コーナーを特定する必要がある。コーナーポイントが正しく特定されない場合、一部のエッジが間違った辺に割り当てられ、それらのエッジが外れ値になる可能性がある。
一般的に、分類における誤差は、回帰問題に正規分布しない誤差をもたらす。そのような場合、誤差は、正規誤差をモデル化するためのガウス分布と、不完全な分類による外れ値をモデル化するための裾野の広い分布を組み合わせた混合分布によってモデル化される場合がある。
コーナーを推定する最良の方法は、エッジ点に直線をフィッティングする手法を1つだけ使用し、その直線の交点を計算することである。この手法は、コーナーを丸めるコーナー検出演算子によって生じる誤差を補正し、局所情報のみを使用するコーナー検出器を使用するよりも正確である。
2本の直線に対する暗黙の方程式が与えらると、 \[ \begin{align} a_1x+b_1y+c_1&= 0 \tag{6.50} \\ \\ a_2x+b_2y+c_2 &= 0 \tag{6.51} \end{align} \] 交点の位置は \[ \begin{align} y &= \frac{c_1a_2-c_2a_1}{a_1b_2-a_2b_1} \tag{6.52} \\ \\ x &= \frac{c_2b_1-c_1b_2}{a_1b_2-a_2b_1} \tag{6.53} \end{align} \] \(a_1b_2-a_2b_1\) がゼロに近い場合、直線はほぼ平行であり、交差させることはできない。
コーナーを検出する良い方法は、輪郭線に沿った \(2n + m\) 個のエッジ点の連続するサブリストに直線のペアを当てはめることである。パラメーター \(n\) は、正確な直線の当てはめに必要なエッジ点の数であり、パラメーター \(m\) は、コーナーの辺の間でスキップするエッジ点の数である。ギャップは、コーナーの丸みを帯びた部分にあるエッジ点をスキップする。コーナーは、\(a_1b_2-a_2b_1\) の大きさを閾値と比較することで検出される。
誤差が正規分布から生じていない場合、最小二乗法は最適な適合基準ではない。図6.12は、データセットに外れ値が含まれている場合に最小二乗回帰が遭遇する問題の例を示している。1つの外れ値だけでも、回帰直線は正しい位置から大きく離れてしまう。ロバスト回帰法では、データポイントのさまざまなサブセットを試し、最も適合度の高いサブセットを選択する。
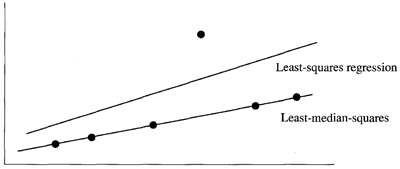
図6.12: 外れ値を含むデータセットに最小二乗回帰法とロバスト手法を用いて曲線を当てはめた場合の違いを示す図解。
図6.13に示す物理的なアナロジーは、この議論をより明確にするかもしれない。平面上の点群の重心を求めたいと想像してもらいたい。同じバネ定数を持つバネを、固定点と自由に移動できる小さな物体に取り付ける。物体は、点の位置の平均に引っ張られる。バネは、位置エネルギーのバネ方程式を通じて、最小二乗ノルムを実現する。この物理的なアナロジーは、各点と平均の差である残差の二乗和を最小化するという基準から平均の計算を導くことに対応している。ここで、点の1つが移動可能だと仮定する。この点をてこ点と呼ぶ。てこ点を十分に遠くに引っ張ることで、平均の位置を任意の点に移動させることができる。これは、最小二乗基準に基づく推定値が外れ値に対して極めて敏感であることを示している。たった1つの外れ値でも、推定値が台無しになる可能性がある。理想的には、外れ値に接続されたバネを壊して推定値に影響を与えないようにしたい。バネ定数を変更して遠く離れた点が推定値にほとんど影響を与えないようにすることは、影響関数に基づくロバスト推定量の実装に相当する。外れ値に接続されたバネを壊すことは、サンプルの一貫性のあるサブセットを決定するリサンプリング方式に相当する。リサンプリング方式では、ランダムなサブセットを繰り返し抽出し、最良の推定値をもたらすサブセットを選択する。リサンプリングアルゴリズムの例としては、ランダムサンプルコンセンサス法、最小中央値二乗回帰法、その他の回帰におけるコンピュータ集約型手法などがある。
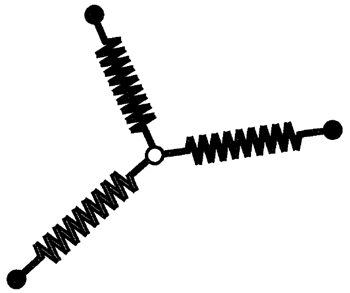
図6.13: 最小二乗法が外れ値に対してどれほど敏感であるかを示す物理的なアナロジー。たとえ1つの外れ値であっても、最小二乗法は役に立たなくなる。
バネのアナロジーは線型回帰にも適用でき、同じ結論が得られる。つまり、たった一つの外れ値でも回帰推定値は歪むということだ。\(n\) 次の線型多変量モデルは次式で表される。 \[ \hat{y}_i=\hat{\theta}_1x_{i1}+\hat{\theta}_2x_{i2}+\cdots+\hat{\theta}_nx_{in} \tag{6.54} \] \(i\)番目のデータポイントについて、\(\hat{\theta}_i\)はモデルパラメータ\(\theta_i\)の推定値である。各データポイントの残差(推定モデルからのデータポイントの偏差)は\(r_i=y_i-\hat{y}_i\)です。最小二乗回帰では、モデルパラメータの推定値は、残差の二乗和を最小化することで与えられる。 \[ \min_\hat{\theta}\sum_{i=1}^n r_i^2 \tag{6.55} \] 上で説明したバネの例えでわかるように、データポイントの1つだけが外れ値であれば、モデルパラメータは任意に設定できる。
多くの場合、ノイズと外れ値は混合分布としてモデル化できる。これは、ノイズをモデル化する正規分布と外れ値を考慮する裾の広い分布の線形結合である。この場合、小さな誤差については線形二乗ノルムに似たノルムを持ち、大きな誤差には鈍感なノルムを持つ推定値を定式化することで外れ値を無視することが理にかなっている。これは影響関数アプローチと呼ばれる。
ブレークダウンポイントとは、任意の程度に誤りがあっても推定アルゴリズムが任意の誤った推定値を生成することのない、データポイントの最小割合のことである[207]。\(Z\)を\(n\)個のデータポイントの集合とする。集合\(Z^\prime\)は、集合\(Z\)の\(m\)個のポイントを任意の値に置き換えたものであるとする。回帰推定量を\(\hat{\theta}=T(Z)\)と表記する。外れ値による推定値のバイアスは、次のように与えられる。 \[ Bias = \sup_{Z^\prime} ||T(Z^\prime) - T(Z) || \tag{6.56} \] ブレークダウンポイントの背後にある考え方は、外れ値の数 \(m\) がデータ点数 \(n\) に対する割合として増加するにつれて、バイアスがどうなるかを考えることである。データ点は任意の値に置き換えられるため、\(m\) と \(n\) の比率によっては、バイアスは潜在的に無制限になる可能性がある。これがブレークダウンポイントである。ブレークダウンポイントより下の場合、回帰推定値は外れ値を完全に棄却できるか、外れ値が推定値にわずかな影響しか与えないかのどちらかである。ブレークダウンポイントを超えると、外れ値によって推定値は任意の答えを導き出す可能性がある。つまり、答えは外れ値に依存し、正当なデータには依存しないということである。言い換えれば、推定値によって得られる結果は予測不可能である。ブレークダウンポイントは次のように定義される。 \[ \epsilon_n^* = \min \Big\{\frac{m}{n} : Bias(m;T, Z)\; is\; infinite\Big\} \tag{6.57} \] 最小二乗回帰では\(\epsilon_n^* = 1/n\)となり、データ点数が増えると極限では\(\epsilon_\infty^*= 0\)となる。言い換えれば、最小二乗回帰は外れ値に対する耐性がなく、たった一つの外れ値でも結果を完全に台無しにする可能性がある。
最小中央値二乗回帰は実装が非常に簡単な手法であり、外れ値の割合が高い場合の回帰問題の解決に非常に効果的であることが証明されている。最小中央値二乗回帰は、データセット内の最大50%の外れ値を許容する。つまり、データセット内のデータポイントの最大半分は、回帰結果に大きな影響を与えることなく、任意の値を取ることができる。
最小中央値二乗回帰では、モデルパラメータの推定値は 残差の二乗の中央値を最小化することで与えられる。 \[ \min_{\hat{\theta}} \underset{i}{med}\; r_i^2 \tag{6.58} \] 最小中央値二乗回帰アルゴリズムは、アルゴリズム 6.3 で説明されている。
アルゴリズム 6.3 最小中央値二乗回帰
線形モデルには \(n\) 個のデータ点と \(p\) 個のパラメータがあると仮定する。
フィッティング手順は、残差の二乗の中央値が十分に小さいフィッティングが見つかるまで、または事前に決定した再サンプリングステップ数まで繰り返される。
中央値には50%の破綻点があり、この性質は最小中央値二乗回帰[207]にも当てはまる。言い換えれば、たとえデータ点の半分が外れ値であっても、回帰推定値は深刻な影響を受けない。もしデータ点の50%以上が外れ値である場合、最小中央値二乗回帰はうまく機能しない可能性があり、ハフ変換などのより強力な手法を使用する必要がある。
ここ数年、投票メカニズムを用いたパラメータ推定手法の利用が増加している。最も一般的な投票手法の一つがハフ変換である。ハフ変換では、曲線上の各点が複数のパラメータの組み合わせに投票し、過半数の票を獲得したパラメータが勝者と宣言される。この手法を用いてデータに直線を当てはめることを考えてみよう。直線の方程式を考える。 \[ y=mx+c \tag{6.59} \] 上記の式において、\(x\) と \(y\) は観測値、\(m\) と \(c\) はパラメータを表している。パラメータの値が与えられれば、点の座標間の関係が明確に指定される。上記の式を次のように書き直してみよう。
\[ \rho= x\cos\theta+ y\sin\theta \tag{6.61} \] ほぼ垂直な線に関する問題を回避するため、明示的な形式ではなく \((x,y)\) が使用される。エッジ点 \((\rho,\theta)\) は \((\rho,\theta)\) パラメータ空間にマッピングされる。
直線の場合、上に示したように、この直線上に \(n\) 個の点があるとすると、これらの点は図6.14に示すように、パラメータ空間における直線の族に対応する。これらの直線はすべて、パラメータ空間の点\((m,c)\)を通る。この点は、元の直線のパラメータを与える。
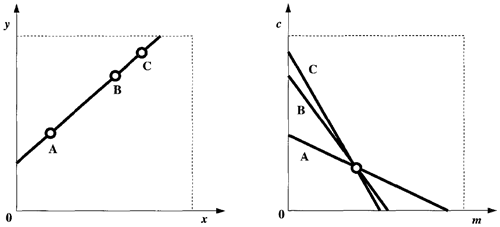
画像内の \(n\) 点に最もよく合う直線を見つけたい場合、画像空間からパラメータ空間への上記のマッピングを使用できる。ハフ変換と呼ばれるこのアプローチでは、パラメータ空間を離散パラメータ値を表す累算器の配列として表現する。画像内の各点は、変換式に従って複数のパラメータを選択する。直線を特徴付けるパラメータを見つけるには、パラメータ空間のピークを検出する必要がある。この基本的な考え方は、アルゴリズム6.4で詳しく説明されている。
アルゴリズム 6.4 ハフ変換アルゴリズム
ハフ変換では、エッジ点を事前にグループ化したりリンクしたりする必要がなく、対象の曲線に沿って存在するエッジ点は、画像内のエッジのごく一部に過ぎない場合がある。特に、実際に曲線に沿って存在するエッジの数は、シーン内のエッジ数の半分未満である可能性があり、ほとんどのロバスト回帰法は適用できない。ハフ変換の背後にある仮定は、大量のノイズが存在する場合、画像内のエッジの最大数を満たすパラメータ空間内の点を見つけることが最善の策であるというものである。パラメータ空間のピークが複数のアキュムレータをカバーする場合、ピークを含む領域の重心がパラメータの推定値となる。
画像内にモデルに一致する曲線が複数ある場合、パラメータ空間には複数のピークが存在することになる。各ピークを検出し、ピークに対応する曲線インスタンスに関連付けられたエッジを削除し、残りの曲線の検出を、ピークが有意でなくなるまで続けることは可能である。ただし、ピークが有意かどうかを判断するのは難しい場合がある。
ハフ変換のもう一つの問題は、離散パラメータ空間のサイズがパラメータ数の増加に伴って急速に増大することである。円弧の場合、パラメータ空間は3次元だが、他の曲線の場合、次元数はさらに高くなることがある。アキュムレータの数は空間の次元とともに指数関数的に増加するため、複雑なモデルではハフ変換の計算効率が非常に悪くなる可能性がある。ハフ変換の性能を向上させるための手法がいくつか提案されている。1つの手法は、境界の勾配情報を用いてパラメータ空間における計算量を削減する。曲線モデルが円であると仮定する。このモデルには3つのパラメータがある。円の中心に関するパラメータが2つ、円の半径に関するパラメータが1つである。エッジの勾配角度が利用可能な場合、これは自由度の数を減少させる制約となり、パラメータ空間の必要サイズも削減される。円の中心から各辺へのベクトルの方向は勾配角によって決定され、半径の値だけが未知パラメータとなる。パラメータ空間のサイズを縮小するために使用できる他の方法もある。
勾配角度を用いてパラメータ空間のサイズを縮小する方法の詳細は、円フィッティングで説明されている。アルゴリズムの詳細はアルゴリズム6.5に記載されている。円の暗黙方程式は
\[
(x-a)^2+(y-b)^2=r^2 \tag{6.62}
\]
極座標における円の媒介変数方程式は
\[
\begin{align}
x &= a+r\cos\theta \tag{6.63} \\
\\
y &= b+r\sin\theta \tag{6.64}
\end{align}
\]
円のパラメータを解いて次の方程式を得る。
\[
\begin{align}
a &= x-r\cos\theta \tag{6.65} \\
\\
b &= y-r\sin\theta \tag{6.66}
\end{align}
\]
エッジ点 \((x, y)\) における勾配角度 \(\theta\) が与えられたとき、\(\cos\theta\) と \(\sin\theta\) を計算する。
これらの値は、エッジ検出の副産物として既に得られている可能性があることに注意。上記の2つの式から半径を消去すると、次の式が得られる。
\[
b=a\tan\theta-x\tan\theta+y \tag{6.67}
\]
アルゴリズム 6.5 円フィッティングアルゴリズム
これは、パラメータ空間における累算器を更新するための式である。 位置 \((x, y)\) にあるエッジの方向 \(\theta\) の各エッジ点について、式 6.67 で示されるリンクに沿って、\((a, b)\) パラメータ空間における累算器を増分する。
半径が分かっている場合は、次のように与えられる点\((a, b)\)の累算器を増分するだけでよい。 \[ \begin{align} a &= x-r\cos\theta \tag{6.69} \\ \\ b &= y-r\sin\theta \tag{6.70} \end{align} \]
ハフ変換によって検出される曲線は、媒介変数方程式で記述される必要はない。ハフ変換は、テンプレートマッチングを効率的に実装する投票アルゴリズム(アルゴリズム6.6を参照)に一般化できる。
アルゴリズム6.6は、効率的なアクセスのために、物体境界の形状をテーブルに符号化する。物体上の1点が参照点として選択される。定義により、画像内の参照点の位置は物体の位置となる。画像上の勾配点(x, y)における勾配角θの各点について、参照点の可能な位置は次のように与えられる。 \[ \begin{align} a &= x-r(\theta)\cos\left(\alpha(\theta)\right) \tag{6.71}\\ \\ b &= y-r(\theta)\sin\left(\alpha(\theta)\right) \tag{6.72} \end{align} \]
アルゴリズム 6.6 一般化ハフ変換
それぞれの参照点の位置は増加します。パラメータ空間におけるピークの位置が、物体の位置の推定値となる。この手法をスケールや回転の変化に適応させるように一般化することは容易ではない。
閉じた輪郭線上の位置は周期関数であるため、フーリエ級数を用いて輪郭線を近似することができる。輪郭線近似の分解能は、フーリエ級数の項数によって決まる。
物体の境界が座標列\(\mathbf u(n) = [x(n), y(n)],\; for\; n = 0,1,2,..., N-1\)で表されるとする。各座標ペアは複素数として表すことができ、 \[ u(n) = x(n) +jy(n) \tag{6.73} \] \(n = 0,1,2,...,N-1\) の場合。言い換えれば、\(x\) 軸は実軸として扱われ、\(y\) 軸は複素数列の虚軸として扱われる。閉境界の場合、この列は周期 \(N\) で周期的であり、境界は1次元で表現されることに注意。
1次元シーケンス \(u(n)\) の離散フーリエ変換(DFT)表現は次のように定義される。 \[ \begin{align} u(n) &= \sum_{k=0}^{N-1} a(k)e^{\frac{j2\pi kn}{N}} 0\leq n\leq N-1 \tag{6.74} \\ \\ a(k) &= \frac{1}{N}\sum_{n=0}^{N-1} u(n)e^{\frac{-j2\pi kn}{N}} 0\leq k\leq N-1 \tag{6.75} \end{align} \] 複素係数\(a(k)\)は境界のフーリエ記述子と呼ばれる。
フーリエ記述子は閉曲線の簡潔な表現である。しかし、級数の低次の項のみを用いた低解像度近似は、さらに簡潔な表現として用いることができる。最初の\(M\)個の係数のみを用いる場合(\(k > M-1\)に対して\(a(k) = 0\)と設定することと等価)、\(u(n)\)の以下の近似が得られる。 \[ \hat{u}(n)=\sum_{k=0}^{M-1} a(k) e^{\frac{j2\pi kn}{N}} 0\leq n\leq N-1 \tag{6.76} \] 境界の各要素 \(u(n)\) を得るのに \(M\) 個の項しか使用されないが、\(n\) は依然として \(0\) から \(N-1\) の範囲にある。言い換えれば、近似境界には同じ数の点が含まれるが、各点を再構築する際に使用される項の数はそれほど多くない。
境界の単純な幾何学的変換(並進、回転、拡大縮小など)は、境界のフーリエ記述子(演習6.18参照)の単純な演算と関連している。そのため、境界マッチングにおいてフーリエ記述子を用いることは魅力的である。しかし、フーリエ記述子は遮蔽された形状を扱う際に問題を抱えている。他の境界表現を用いて同様の記述子を得る方法は他にもある。