ImageNet LSVRC-2010 コンテストの 120 万枚の高解像度画像を 1000 種類のクラスに分類するために、大規模な深層畳み込みニューラル ネットワークをトレーニングした。テストデータでは、トップ 1 とトップ 5 のエラー率がそれぞれ 37.5% と 17.0% となり、これは以前の最先端技術よりも大幅に改善されている。6000 万のパラメーターと 650,000 のニューロンを持つニューラル ネットワークは、5 つの畳み込み層 (その一部には最大プーリング層が続く) と、最後の 1000 通りのソフトマックスを持つ 3 つの完全接続層で構成されている。トレーニングを高速化するために、非飽和ニューロンと、畳み込み演算の非常に効率的な GPU 実装を使用した。完全接続層でのオーバーフィッティングを減らすために、非常に効果的であることが証明された、最近開発された「ドロップアウト」と呼ばれる正規化手法を採用した。我々はこのモデルの変種をILSVRC-2012コンテストにも参加させ、2位が達成した26.2%に対して、トップ5のテストエラー率15.3%を達成して優勝した。
現在の物体認識のアプローチでは、機械学習手法が必須である。そのパフォーマンスを向上させるには、より大きなデータセットを収集し、より強力なモデルを学習し、オーバーフィッティングを防ぐためのより優れた手法を使用する。最近まで、ラベル付き画像のデータセットは比較的小さく、数万枚の画像程度であった (例: NORB [16]、Caltech-101/256 [8、9]、CIFAR-10/100 [12])。このサイズのデータセットでは、特にラベル保持変換が追加されている場合は、単純な認識タスクを非常にうまく解決できる。たとえば、MNIST 数字認識タスクの現在の最高のエラー率 (<0.3%) は、人間のパフォーマンスに近づいている [4]。ただし、現実的な設定の物体はかなりの変動性を示すため、物体認識を学習するには、はるかに大きなトレーニング セットを使用する必要がある。実際、小規模な画像データセットの欠点は広く認識されているが(例:Pinto et al. [21])、数百万枚の画像を含むラベル付きデータセットを収集できるようになったのはごく最近のことである。新しい大規模なデータセットには、数十万枚の完全にセグメント化された画像で構成されるLabelMe [23]や、22,000を超えるカテゴリの1500万枚を超えるラベル付き高解像度画像で構成されるImageNet [6]などがある。
数百万枚の画像から数千の物体について学習するには、学習能力の大きいモデルが必要である。しかし、物体認識タスクの複雑さは計り知れないため、ImageNet のような大規模なデータセットでもこの問題を特定することはできない。そのため、モデルには、不足しているすべてのデータを補うための事前知識も豊富に必要である。畳み込みニューラル ネットワーク (CNN) は、そのようなモデルの 1 つのクラスを構成する [16、11、13、18、15、22、26]。CNN の能力は深さと幅を変えることで制御でき、画像の性質 (つまり、統計の定常性とピクセル依存性の局所性) について強力かつほぼ正しい仮定を立てる。したがって、同様のサイズのレイヤーを持つ標準的なフィードフォワード ニューラル ネットワークと比較すると、CNN は接続とパラメーターがはるかに少ないため、トレーニングが容易であるが、理論上最高のパフォーマンスはわずかに劣る程度である。
CNN の魅力的な品質と、そのローカル アーキテクチャの相対的な効率性にもかかわらず、 CNN を高解像度の画像に大規模に適用するには、依然として法外なコストがかかる。幸いなことに、 現在の GPU は、2D 畳み込みの高度に最適化された実装と組み合わせることで、 非常に大規模な CNN のトレーニングを容易にするのに十分なパワーを備えており、ImageNet などの最近のデータセットには、 このようなモデルを深刻なオーバーフィッティングなしでトレーニングするのに十分なラベル付きサンプルが含まれている。
この論文の具体的な貢献は次のとおり。ILSVRC-2010 および ILSVRC-2012 コンペティション [2] で使用された ImageNet のサブセットで、これまでで最大の畳み込みニューラル ネットワークの 1 つをトレーニングし、これらのデータセットでこれまでに報告された中で最も優れた結果を達成した。2D 畳み込みと畳み込みニューラル ネットワークのトレーニングに固有のその他のすべての操作の高度に最適化された GPU 実装を作成し、公開した1。我々のネットワークには、パフォーマンスを向上させ、トレーニング時間を短縮する新しく珍しい機能が多数含まれている。詳細はセクション 3 で説明する。ネットワークのサイズが大きいため、ラベル付きトレーニング例が 120 万個あっても、オーバーフィッティングが大きな問題になった。そのため、オーバーフィッティングを防ぐための効果的な手法をいくつか使用した。これについてはセクション 4 で説明する。最終的なネットワークには、5 つの畳み込み層と 3 つの完全接続層が含まれており、この深さが重要であると思われる。畳み込み層 (各層にはモデルのパラメータの 1% 以下しか含まれない) を削除すると、パフォーマンスが低下することがわかった。
1 http://code.google.com/p/cuda-convnet/ (アクセスできない)
結局のところ、ネットワークのサイズは、現在の GPU で利用可能なメモリの量と、許容できるトレーニング時間によって主に制限される。我々のネットワークは、2 つの GTX 580 3GB GPU でトレーニングするのに 5 日から 6 日かかる。すべての実験から、より高速な GPU とより大きなデータセットが利用可能になるまで待つだけで、結果を改善できることが示唆される。
ImageNet は、約 22,000 のカテゴリに属する 1,500 万枚を超えるラベル付き高解像度画像のデータセットである。画像は Web から収集され、Amazon の Mechanical Turk クラウドソーシング ツールを使用して人間のラベル付け担当者によってラベル付けされた。2010 年から、Pascal Visual Object Challenge の一環として、ImageNet Large-Scale Visual Recognition Challenge (ILSVRC) と呼ばれる毎年恒例のコンテストが開催されている。ILSVRC では、1,000 のカテゴリごとに約 1,000 枚の画像を含む ImageNet のサブセットを使用する。合計で、約 120 万枚のトレーニング画像、50,000 枚の検証画像、150,000 枚のテスト画像がある。
ILSVRC-2010 は、テスト セット ラベルが利用できる唯一の ILSVRC バージョンであるため、ほとんどの実験はこのバージョンで実行された。ILSVRC-2012 コンテストにもモデルをエントリーしたため、セクション 6 では、テスト セット ラベルが利用できないこのバージョンのデータセットの結果も報告する。ImageNet では、通常、トップ 1 とトップ 5 の 2 つのエラー レートが報告される。トップ 5 エラー レートは、モデルによって最も可能性が高いと見なされる 5 つのラベルの中に正しいラベルが含まれていないテスト画像の割合である。
ImageNet は可変解像度の画像で構成されているが、我々のシステムでは一定の入力次元が必要である。 そのため、画像を 256×256 の固定解像度にダウンサンプリングした。長方形の画像の場合、まず短い辺の長さが 256 になるように画像のサイズを変更し、次に結果の画像から中央の 256×256 のパッチを切り出した。各ピクセルからトレーニング セットの平均値を減算する以外は、画像の前処理は行っていない。そのため、ピクセルの (中央の) 生の RGB 値でネットワークをトレーニングした。
我々のネットワークのアーキテクチャは、図 2 にまとめられている。このネットワークには、5 つの畳み込み層と 3 つの完全接続層を含む 8 つの学習済み層がある。以下では、我々のネットワーク アーキテクチャの斬新な、または珍しい機能のいくつかについて説明する。セクション 3.1 ~ 3.4 は、我々の推定した重要度に従って、最も重要なものから順に並べられている。
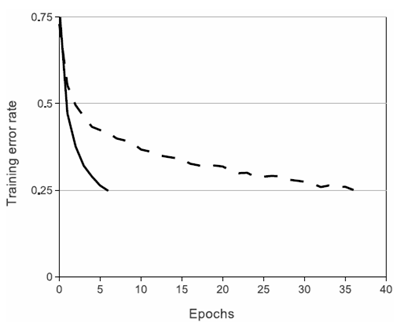
ニューロンの出力 \(f\) をその入力 \(x\) の関数としてモデル化する標準的な方法は、\(f(x) = tanh(x)\) または \(f(x) = (1 + e^{-x})^{-1}\) を使用することである。勾配降下法によるトレーニング時間に関して言えば、これらの飽和非線形性は、非飽和非線形性 \(f(x) = max(0, x)\) よりもはるかに低速である。Nair と Hinton [20] に従い、この非線形性を持つニューロンを Rectified Linear Units (ReLU) と呼ぶ。ReLU を持つ深層畳み込みニューラルネットワークは、tanh ユニットを持つ同等のニューロンよりも数倍速くトレーニングされる。これは、特定の 4 層畳み込みネットワークの CIFAR-10 データセットで 25% のトレーニング誤差に達するために必要な反復回数を示す図 1 に示されている。このグラフは、従来の飽和ニューロンモデルを使用していた場合、この研究でこれほど大規模なニューラルネットワークを実験することはできなかったことを示している。
CNN における従来のニューロン モデルの代替案を検討したのは、我々が初めてではない。たとえば、Jarrett ら [11] は、非線形性 \(f(x) = |tanh(x)|\) が、Caltech-101 データセットでローカル平均プーリングに続くコントラスト正規化のタイプで特にうまく機能すると主張している。ただし、このデータセットでは、主にオーバーフィッティングを防ぐことが懸念されるため、彼らが観察している効果は、ReLU を使用した場合に報告されるトレーニング セットへの適合の加速能力とは異なる。より高速な学習は、大規模なデータセットでトレーニングされた大規模モデルのパフォーマンスに大きな影響を与える。
図 1: ReLU を使用した 4 層畳み込みニューラル ネットワーク (実線) は、CIFAR-10 で 25% のトレーニング エラー率に達するが、これは tanh ニューロンを使用した同等のネットワーク (破線) の 6 倍の速さである。各ネットワークの学習率は、トレーニングを可能な限り高速にするために個別に選択された。いかなる種類の正規化も使用されていない。ここで実証された効果の大きさはネットワーク アーキテクチャによって異なるが、ReLU を使用したネットワークは、飽和ニューロンを使用した同等のネットワークよりも一貫して数倍速く学習される。
1 つの GTX 580 GPU には 3 GB のメモリしかないため、その GPU でトレーニングできるネットワークの最大サイズが制限される。120 万のトレーニング サンプルがあれば、1 つの GPU に収まらないほど大きいネットワークをトレーニングするのに十分であることがわかった。そのため、2 つの GPU にネットを分散した。現在の GPU は、ホスト マシンのメモリを経由せずに、互いのメモリを直接読み書きできるため、GPU 間の並列化に特に適している。我々が採用している並列化スキームでは、基本的にカーネル (またはニューロン) の半分を各 GPU に配置するが、もう 1 つのトリックがある。GPU は特定のレイヤーでのみ通信する。つまり、たとえば、レイヤー 3 のカーネルはレイヤー 2 のすべてのカーネル マップから入力を受け取る。ただし、レイヤー 4 のカーネルは、同じ GPU にあるレイヤー 3 のカーネル マップからのみ入力を受け取る。接続パターンの選択はクロスバリデーションにとって問題であるが、これにより、通信量を計算量の許容可能な割合になるまで正確に調整できる。
結果として得られるアーキテクチャは、Cire¸san ら [5] が採用した「列状」CNN のアーキテクチャと多少似ているが、列が独立していない点が異なる (図 2 を参照)。この方式では、1 つの GPU でトレーニングされた各畳み込み層のカーネル数が半分のネットと比較して、トップ 1 およびトップ 5 のエラー率がそれぞれ 1.7% と 1.2% 削減される。2 GPU ネットのトレーニング時間は、1 GPU ネット2 よりもわずかに短くなる。
2 1 GPU ネットのカーネル数は、最終畳み込み層では 2 GPU ネットと同じ数である。これは、ネットのパラメータのほとんどが、最終畳み込み層を入力とする最初の完全接続層にあるためである。そのため、2 つのネットのパラメータ数をほぼ同じにするために、最終畳み込み層 (およびその後の完全接続層) のサイズを半分にしなかった。したがって、この比較は 1 GPU ネットに有利に偏っている。1 GPU ネットは 2 GPU ネットの「半分のサイズ」よりも大きいためである。
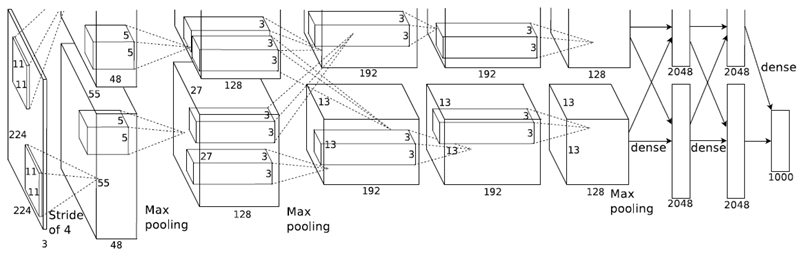
図 2: CNN のアーキテクチャの図。2 つの GPU 間の責任区分が明確に示されている。1 つの GPU は図の上部にあるレイヤー部分を実行し、もう 1 つの GPU は下部にあるレイヤー部分を実行する。GPU は特定のレイヤーでのみ通信する。ネットワークの入力は 150,528 次元で、ネットワークの残りのレイヤーのニューロン数は 253,440–186,624–64,896–64,896–43,264–4096–4096–1000 で表される。
ReLU には、飽和を防ぐために入力正規化を必要としないという望ましい特性がある。少なくともいくつかのトレーニング例が ReLU に正の入力を生成する場合、そのニューロンで学習が行われる。ただし、次のローカル正規化スキームが一般化に役立つことがわった。カーネル \(i\) を位置 \((x, y)\) に適用し、次に ReLU 非線形性を適用して計算されたニューロンのアクティビティを \(a_{x,y}^i\) で表すと、応答正規化活性度関数 \(b_{x,y}^i\) は次の式で与えられる。 \[ b_{x,y}^i=a_{x,y}^i/\left(k+\alpha\sum_{j=max(0,i-n/2)}^{min(N-1,i+n/2)}(a_{x,y}^j)^2\right)^\beta \]
ここで、合計は同じ空間位置にある \(n\) 個の「隣接する」カーネル マップに渡って行われ、\(N\) はレイヤー内のカーネルの総数である。カーネル マップの順序は当然任意であり、トレーニング開始前に決定される。この種の応答正規化は、実際のニューロンに見られるタイプにヒントを得た一種の側方抑制を実装し、異なるカーネルを使用して計算されたニューロン出力間で大きなアクティビティの競合を生み出す。定数 \(k,n,\alpha\)、および \(\beta\) は、検証セットを使用して値が決定されるハイパーパラメーターである。ここでは \(k = 2、n = 5、\alpha= 10^{-4}\)、および \(\beta= 0.75\) を使用した。この正規化は、特定のレイヤーで ReLU 非線形性を適用した後に適用した (セクション 3.5 を参照)。
この方式は、Jarrett ら [11] のローカルコントラスト正規化方式と似ているが、平均活性化を減算しないため、我々の方式は「明るさ正規化」と呼ぶ方が正確であろう。応答正規化により、トップ 1 とトップ 5 のエラー率がそれぞれ 1.4% と 1.2% 減少する。また、CIFAR-10 データセットでこの方式の有効性も検証した。4 層の CNN は、正規化なしで 13% のテストエラー率を達成し、正規化ありで 11% を達成した3。
3 スペースの制約により、このネットワークを詳しく説明することはできないが、ここで提供されているコードとパラメータ ファイルによって正確に指定される: http://code.google.com/p/cuda-convnet/ (アクセスできない)
CNN のプーリング層は、同じカーネル マップ内の隣接するニューロン グループの出力を要約する。従来、隣接するプーリング ユニットによって要約される近傍は重複しない (例: [17, 11, 4])。より正確には、プーリング層は、s ピクセル間隔で配置されたプーリング ユニットのグリッドで構成されていると考えられる。各プーリング ユニットは、プーリング ユニットの位置を中心とするサイズ \(z\times z\) の近傍を要約する。\(s = z\) に設定すると、CNN で一般的に使用される従来のローカル プーリングが得られる。\(s < z\) に設定すると、重複プーリングが得られる。これは、\(s = 2\) および \(z = 3\) で、ネットワーク全体で使用されているものである。この方式では、同等の次元の出力を生成する重複しない方式 \(s = 2、z = 2\) と比較して、トップ 1 とトップ 5 のエラー率がそれぞれ 0.4% と 0.3% 減少する。通常、トレーニング中に、重複プーリングを使用するモデルでは、オーバーフィットがわずかに困難になることがわかる。
これで、CNN の全体的なアーキテクチャを説明する準備が整った。図 2 に示すように、ネットには重みを持つ 8 つの層が含まれている。最初の 5 つは畳み込み層で、残りの 3 つは完全接続層である。最後の完全接続層の出力は、1000通りのソフトマックスに送られ、1000 個のクラス ラベルにわたる分布が生成される。ネットワークは、多項ロジスティック回帰の目的を最大化する。これは、予測分布の下での正しいラベルの対数確率のトレーニング ケース全体の平均を最大化することと同じである。
2 番目、4 番目、5 番目の畳み込み層のカーネルは、同じ GPU 上にある前の層のカーネル マップにのみ接続される (図 2 を参照)。3 番目の畳み込み層のカーネルは、2 番目の層のすべてのカーネル マップに接続される。完全接続層のニューロンは、前の層のすべてのニューロンに接続される。応答正規化層は、1 番目と 2 番目の畳み込み層の後に続く。セクション 3.4 で説明した種類の最大プーリング層は、応答正規化層と 5 番目の畳み込み層の後に続く。ReLU 非線形性は、すべての畳み込み層と完全接続層の出力に適用される。
最初の畳み込み層は、224×224×3 の入力画像を、4 ピクセルのストライド (カーネル マップ内の隣接するニューロンの受容野中心間の距離) で、サイズ 11×11×3 のカーネル 96 個でフィルタリングする。2 番目の畳み込み層は、最初の畳み込み層の (応答正規化およびプールされた) 出力を入力として受け取り、サイズ 5×5×48 のカーネル 256 個でフィルタリングする。3 番目、4 番目、および 5 番目の畳み込み層は、プーリング層や正規化層を介さずに相互に接続されている。3 番目の畳み込み層には、サイズ 3×3×256 のカーネル 384 個があり、2 番目の畳み込み層の (正規化およびプールされた) 出力に接続されている。 4 番目の畳み込み層には 3×3×192 サイズのカーネルが 384 個あり、5 番目の畳み込み層には 3×3×192 サイズのカーネルが 256 個ある。完全結合層にはそれぞれ 4096 個のニューロンがある。
我々のニューラル ネットワーク アーキテクチャには 6,000 万のパラメータがある。ILSVRC の 1,000 クラスでは、各トレーニング例で画像からラベルへのマッピングに 10 ビットの制約が課せられるが、これは、かなりのオーバーフィッティングなしにこれほど多くのパラメータを学習するには不十分であることが判明している。以下では、オーバーフィッティングに対処する 2 つの主な方法について説明する。
画像データのオーバーフィッティングを減らす最も簡単で一般的な方法は、ラベル保存変換を使用してデータセットを人工的に拡大することである (例: [25, 4, 5])。我々は 2 つの異なる形式のデータ拡張を採用している。どちらも、変換された画像を元の画像からほとんど計算せずに生成できるため、変換された画像をディスクに保存する必要はない。我々の実装では、GPU が前の画像バッチでトレーニングしている間に、変換された画像は CPU 上の Python コードで生成される。したがって、これらのデータ拡張スキームは、実質的に計算不要である。
データ拡張の最初の形式は、画像変換と水平反射を生成することである。 これは、256×256 の画像からランダムに 224×224 のパッチ (およびその水平反転) を抽出し、抽出したパッチでネットワークをトレーニングすることで実施する4。これにより、トレーニング セットのサイズが 2048 倍に増加するが、結果として得られるトレーニング サンプルは、当然ながら相互依存性が非常に高くなる。このスキームがなければ、ネットワークは大幅なオーバーフィッティングに悩まされ、はるかに小さなネットワークを使用する必要に迫られることになる。テスト時に、ネットワークは 5 つの 224×224 パッチ (4 つのコーナー パッチと中央のパッチ) とその水平反射 (つまり合計 10 個のパッチ) を抽出し、ネットワークのソフトマックス レイヤーによって 10 個のパッチに対して行われた予測を平均化することで予測を行う。
4 これが、図 2 の入力画像が 224×224×3 次元である理由である。
2 番目の形式のデータ拡張は、トレーニング画像の RGB チャネルの強度を変更することである。具体的には、対応する固有値に比例する大きさの RGB ピクセル値のセットに、平均 0、標準偏差 0.1 のガウス分布から抽出されたランダム変数を掛けて PCA を実行する。したがって、各 RGB 画像ピクセル \(I_{xy} = [I_{xy}^R、I_{xy}^G、I_{xy}^B]^T\) に次の量を追加する: \[ [p_1、p_2、p_3][\alpha_1\lambda_1、\alpha_2\lambda_2、\alpha_3\lambda_3]^T \] ここで、\(p_i\) と \(\lambda_i\) はそれぞれ RGB ピクセル値の 3×3 共分散行列の i 番目の固有ベクトルと固有値であり、\(\alpha_i\) は前述のランダム変数である。各 \(\alpha_i\) は、特定のトレーニング画像のすべてのピクセルに対して 1 回だけ描画され、その画像が再度トレーニングに使用されると再描画される。この方式は、自然画像の重要な特性、つまり、物体の同一性が照明の強度と色の変化に対して不変であるという特性をほぼ捉えている。この方式は、トップ 1 エラー率を 1% 以上削減する。
多くの異なるモデルの予測を組み合わせることは、テストエラーを減らすのに非常に効果的な方法であるが[1, 3]、すでにトレーニングに数日かかる大規模なニューラルネットワークにはコストがかかりすぎる。ただし、トレーニング中に約2倍のコストしかかからない、非常に効率的なモデルの組み合わせがある。最近導入された「ドロップアウト」と呼ばれる手法[10]は、各隠れニューロンの出力を確率0.5でゼロに設定することから成る。このように「ドロップアウト」されたニューロンは、フォワードパスには寄与せず、バックプロパゲーションにも参加しない。したがって、入力が提示されるたびに、ニューラルネットワークは異なるアーキテクチャをサンプリングするが、これらのアーキテクチャはすべて重みを共有する。この手法では、ニューロンが特定の他のニューロンの存在に依存できないため、ニューロンの複雑な共適応が削減される。したがって、他のニューロンのさまざまなランダムなサブセットと組み合わせて役立つ、より堅牢な機能を学習する必要がある。テスト時には、すべてのニューロンを使用するが、その出力を 0.5 倍にする。これは、指数関数的に多数のドロップアウト ネットワークによって生成された予測分布の幾何平均を取ることの妥当な近似値である。
図 2 の最初の 2 つの完全接続層ではドロップアウトを使用する。ドロップアウトがないと、ネットワークは大幅なオーバーフィッティングを示す。ドロップアウトにより、収束に必要な反復回数が約 2 倍になる。
我々は、バッチサイズ 128 例、モメンタム 0.9、重み減衰 0.0005 で確率的勾配降下法を使用してモデルをトレーニングした。このわずかな重み減衰がモデルの学習にとって重要であることがわかった。言い換えれば、ここでの重み減衰は単なる正規化ではなく、モデルのトレーニング エラーを削減する。重み \(w\) の更新ルールは、 \[ \begin{align} v_{i+1} &:=0.9\cdot v_i -0.0005\cdot\epsilon\cdot w_i -\epsilon\cdot\left<\frac{\partial L}{\partial w}\mid_{w_i}\right>_{D_i} \\ w_{i+1} &:= w_i + v_{i+1} \end{align} \] ここで、\(i\) は反復インデックス、\(v\) はモーメント変数、\(\epsilon\) は学習率、\(\left<\frac{\partial L}{\partial w}\mid_{w_i}\right>_{D_i}\) は、\(w_i\) で評価された目的関数の w に関する微分の i 番目のバッチ \(D_i\) の平均である。
各層の重みを、標準偏差 0.01 のゼロ平均ガウス分布で初期化した。2 番目、4 番目、5 番目の畳み込み層、および完全接続された隠れ層のニューロン バイアスを定数 1 で初期化した。この初期化により、ReLU に正の入力が提供され、学習の初期段階が加速される。残りの層のニューロンバイアスは定数 0 で初期化した。
すべてのレイヤーに同じ学習率を使用し、トレーニング中は手動で調整した。 我々が従ったヒューリスティックは、現在の学習率で検証エラー率の改善が止まったときに学習率を 10 で割ることである。学習率は 0.01 で初期化され、終了前に 3 回削減された。120 万枚の画像のトレーニング セットを使用して、ネットワークを約 90 サイクルトレーニングした。これには、2 つの NVIDIA GTX 580 3GB GPU で 5 ~ 6 日かかった。
ILSVRC-2010 での結果を表 1 にまとめる。我々のネットワークは、トップ 1 とトップ 5 のテストセットエラー率がそれぞれ 37.5% と 17.0% を達成した5。ILSVRC-2010 の競技中に達成された最高のパフォーマンスは、異なる特徴でトレーニングされた 6 つのスパース コーディング モデルから生成された予測を平均するアプローチで 47.1% と 28.2% だった [2]。それ以降に公開された最高の結果は、2 種類の高密度にサンプリングされた特徴から計算されたフィッシャー ベクトル (FV) でトレーニングされた 2 つの分類器の予測を平均するアプローチで 45.7% と 25.7% である [24]。
5 セクション 4.1 で説明したように、10 個のパッチにわたって予測を平均化しない場合のエラー率は 39.0% と 18.3% である。
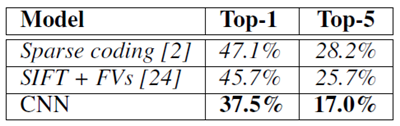
表1: ILSVRC-2010 テスト セットの結果の比較。イタリック体は他のユーザーが達成した最高の結果。
また、ILSVRC-2012 コンテストにもモデルをエントリーし、その結果を表 2 に報告している。ILSVRC-2012 テスト セット ラベルは公開されていないため、試したすべてのモデルのテスト エラー率を報告することはできない。この段落の残りの部分では、検証とテストのエラー率を同じ意味で使用する。これは、経験上、それらの差が 0.1% を超えることはないためである (表 2 を参照)。この論文で説明されている CNN は、トップ 5 のエラー率が 18.2% である。5 つの類似した CNN の予測を平均すると、エラー率は 16.4% になる。最後のプーリング層の上に 6 番目の畳み込み層を追加した 1 つの CNN をトレーニングして、ImageNet Fall 2011 リリース全体 (1,500 万枚の画像、22,000 のカテゴリ) を分類し、それを ILSVRC-2012 で「微調整」すると、エラー率は 16.6% になる。 2011 年秋のリリース全体で事前トレーニングされた 2 つの CNN の予測を前述の 5 つの CNN で平均すると、エラー率は 15.3% になった。2 番目に優れたコンテスト エントリは、さまざまな種類の高密度サンプリングされた特徴から計算された FV でトレーニングされた複数の分類器の予測を平均するアプローチで、エラー率 26.2% を達成した [7]。
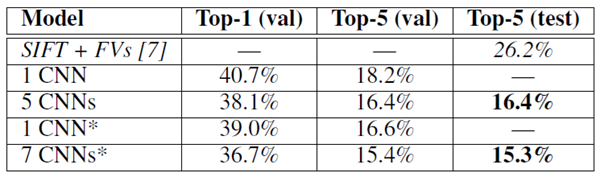
表 2: ILSVRC-2012 検証セットとテスト セットのエラー率の比較。イタリック体は、他の研究者が達成した最高の結果。アスタリスク* の付いたモデルは、ImageNet 2011 Fall リリース全体を分類するために「事前トレーニング」されている。詳細については、セクション 6 を参照。
最後に、10,184 のカテゴリと 890 万枚の画像を含む 2009 年秋バージョンの ImageNet でのエラー率も報告する。このデータセットでは、文献の慣例に従い、画像の半分をトレーニングに、残りの半分をテストに使用する。確立されたテスト セットがないため、分割は必然的に以前の著者が使用した分割とは異なるが、結果に大きな影響はない。このデータセットのトップ 1 およびトップ 5 のエラー率は 67.4% と 40.9% で、これは上記のネットで達成したものであるが、最後のプーリング層の上に 6 番目の畳み込み層が追加されている。このデータセットで公開されている最高の結果は 78.1% と 60.9% である [19]。

図 3 は、ネットワークの 2 つのデータ接続層によって学習された畳み込みカーネルを示している。ネットワークは、さまざまな周波数および方向選択カーネル、およびさまざまな色の塊を学習した。セクション 3.5 で説明した制限された接続の結果として、2 つの GPU によって示される特殊化に注目してもらいたい。GPU 1 のカーネルは主に色に依存しないが、GPU 2 のカーネルは主に色に固有である。この種の特殊化は実行ごとに発生し、特定のランダムな重みの初期化 (GPU の再番号付けを除く) とは無関係である。
図 4 の左側のパネルでは、8 つのテスト画像で上位 5 つの予測を計算して、ネットワークが何を学習したかを定性的に評価している。左上のダニなど、中心から外れたオブジェクトでも、ネットワークによって認識できることに注目してもらいたい。上位 5 つのラベルのほとんどは妥当に見える。たとえば、ヒョウの妥当なラベルと見なされるのは、他の種類の猫だけである。場合によっては (グリル、チェリー)、写真の意図された焦点についてまったく曖昧である。

図4: (左) 8つのILSVRC-2010テスト画像と、モデルによって最も可能性が高いと判断された5つのラベル。各画像の下に正しいラベルが書かれており、正しいラベルに割り当てられた確率も赤いバーで表示される(上位5つに入っている場合)。 (右) 最初の列に5つのILSVRC-2010テスト画像。残りの列には、最後の隠れ層で特徴ベクトルを生成する6つのトレーニング画像が表示されている。
ネットワークの視覚知識を調べる別の方法は、最後の 4096 次元の隠れ層で画像によって誘発される特徴活性化を考慮することである。2 つの画像が小さなユークリッド分離で特徴活性化ベクトルを生成する場合、ニューラル ネットワークの上位レベルではそれらが類似していると見なしていると言える。図 4 は、この基準に従って、テスト セットからの 5 つの画像と、それぞれに最も類似しているトレーニング セットからの 6 つの画像を示している。ピクセル レベルでは、取得されたトレーニング画像は、通常、最初の列のクエリ画像と L2 で近くないことに注意。たとえば、取得された犬と象はさまざまなポーズで表示される。補足資料では、さらに多くのテスト画像の結果を示している。
2つの4096次元の実数値ベクトル間のユークリッド距離を使用して類似性を計算するのは非効率的であるが、これらのベクトルを短いバイナリコードに圧縮するようにオートエンコーダをトレーニングすることで効率化できる。これにより、画像ラベルを使用しないため、意味的に類似しているかどうかに関係なく、エッジのパターンが似ている画像を検索する傾向がある生のピクセルにオートエンコーダを適用するよりもはるかに優れた画像検索方法が得られる[14]。
我々の結果は、大規模な深層畳み込みニューラル ネットワークが、純粋な教師あり学習を使用して、非常に難しいデータセットで記録破りの結果を達成できることを示している。1 つの畳み込み層を削除すると、ネットワークのパフォーマンスが低下することは注目に値する。たとえば、中間層のいずれかを削除すると、ネットワークのトップ 1 パフォーマンスが約 2% 低下する。したがって、結果を達成するには深さが非常に重要である。
実験を簡素化するため、教師なし事前トレーニングは使用しなかったが、特に、ラベル付きデータの量の増加を伴わずにネットワークのサイズを大幅に増やすのに十分な計算能力が得られれば、教師なし事前トレーニングが役立つと予想している。これまでのところ、ネットワークを大きくし、より長くトレーニングしたため、結果は改善されているが、人間の視覚システムの下側頭経路に一致するには、まだ何桁も桁違いの課題がある。最終的には、静止画像では欠落しているか、はるかにわかりにくい非常に役立つ情報を時間構造から得られるビデオ シーケンスで、非常に大きく深い畳み込みネットを使用したいと考えている。